En este encuentro se repasaron algunos conceptos vistos en encuentros anteriores, tales como la jerarquía de los lenguajes formales (jerarquía de Chomsky), los problemas que tenemos al diseñar una gramática, tales como recursividad por izquierda, y como optimizar estas, mediante factorización y aplanamiento o reemplazo de términos. Y se vieron por primera vez temas tal como el de las gramáticas ambiguas. Para este caso en particular, ya esta explicado en el resumen del encuentro anterior, aunque se explicará de nuevo a continuación.
Gramáticas ambiguas
Si bien no se menciono en clase, existen gramáticas que son ambiguas y cual sería este caso? En este caso si tenemos una gramática que nos permite modelar una estructura clásica como if/else de este estilo:
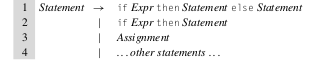
Vemos que nuestro if puede ser un if Expr then Stmt siempre y el bloque else sería opcional. Ahora imaginemos que tenemos un caso en el que tenemos un if anidado en el bloque then de otro if:
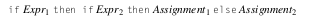
En este caso nuestro parser no sabrá a que contexto pertenece nuestro bloque else cuando lo parseemos con un top-down parser, y se podrían generar dos resultados distintos de AST, uno en el que el bloque else pertenece al segundo if anidado, que sería nuestro escenario deseado:
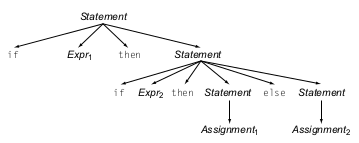
Y otro resultado en el que el bloque else pertenece al primer if
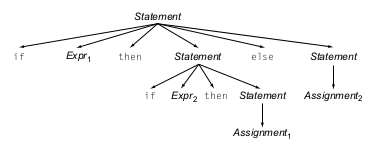
En este caso se dice que la gramática es ambigua ya que una vez armado uno de los dos AST no sabremos si el resultado que generamos era el deseado o no.
Para eliminar la ambigüedad en este ejemplo, basta con reescribir nuestra gramática de una manera que podamos distinguir cuando tenemos una gramática del tipo if/then o if/then/else. Entonces nuestra gramática podría quedar como:

Más sobre parsers
Si bien ya habíamos visto un poco de teoría sobre los parsers veamos un poco más en detalle una simple clasificación y ejemplos de los parsers más sencillos de manera teórica para entender un poco sobre los problemas que pueden aparecer cuando estemos armando nuestro parser usando los parser combinators de Scala.
Los dos tipos básicos de parsers que veremos son los parsers LL y LR.
Que significan los acrónimos?
L: significa que se parsea la entrada de izquierda a derecha de manera imperativa, esto aplica para ambas clasificaciones.
Para los parsers LL, la segunda L se refiere a la transformación que produce, o sea, la derivación que vimos con las gramáticas, que en este caso es de izquierda (Left) a derecha. Para los parsers LR, esto se refiere a que las derivaciones son de derecha (Right) a izquierda. Entonces, la manera en la que se realizan las derivaciones iran generando árboles sintácticos que tienen una estructura igual pero su construcción será distinta. Esto se relaciona con el parseo Bottom-up y Top-Down
Parseo Bottom-Up y Top-Down, Comparación
Estos parsers se diferencia en que los Bottom-up, detectan primero los tokens con mayor nivel de detalle y luego las estructuras generales, por ej. Detectaría operaciones algebraicas antes de detectar que esta esta dentro de un método/función. Mientras que los Top-Down parsers primero detectan los nodos principales y luego se irá completando el árbol con los nodos concretos de cada operación. Entonces el órden en el que irán detectando el orden y se armaŕan de los nodos del árbol son distintos dependiendo de uno u otro tipo de parser. Por ej. para una expresión A=B + C*2; D=1, el árbol que se genera es el siguiente:



En el caso que tengamos múltiples reglas que empiezan con el mismo símbolo por izquierda pero su derivación por derecha es distinto, por ej:
A → Ba
A → aaB
entonces esa gramática puede ser manejada eficientemente por un parser bottom-up determinístico pero no puede ser procesado por un parser top down que no tenga backtracking. Entonces se puede decir que los parsers bottom-up pueden manejar un rango de gramáticas más grande que los parsers top-down determinísticos. Los parser bottom-up pueden ser armados mediante un parser shift-reduce como un LALR parser, veremos un poco mas adelante sobre este tipo de parser bottom-up.
Para ambos parsers la estructura que tienen los parsers es la de contar con una tabla de derivaciones en la que estarán presentes las reglas gramaticales y un stack, que se utilizará de diferente manera tanto para parsers LR como LL con backracking. Para evitar el backtracking o adivinar que regla tomar primero, en caso de que existan múltiples reglas para un no terminal, el parser LR puede ver para adelante k tokens de entrada antes de decidir como parsear estos símbolos y que camino elegir. En general k es 1 y no se lo explicita, asi que el caso mas común de LR es LR(1).
Otro tema a tener en cuenta son los problemas a tener en cuenta. Para los parsers LL, las derivaciones son de izquierda a derecha, por lo que si existe recursividad por izquierda entrará en un bucle infinito y nunca se podrá finalizar la ejecución, entonces es importante eliminar esta recursividad previo a la implementación de la gramática en el parser. La metodología para eliminar recursividad por izquierda se vió en el resumen del encuentro anterior. Cuando se elimine este tipo de recursividad, se pasará a tener un esquema de recursividad por derecha, o sea, no eliminamos la recursividad del todo sino que lo hicimos compatible para que se pueda manejar por medio de un parser LL, ahora esta gramática derivada no es compatible con un parser LR, en el que las derivaciones son de derecha a izquierda, entonces para aplicar esta gramática, bastará con pasarle la gramática original con recursividad por izquierda, ya que un parser LR no es afectado por este tipo de gramáticas.
Los parsers LR en general son del tipo LARL, que implementan un tipo de esquema basado en acciones shift and reduce. Dado una serie de tokens de entrada, se usarán estas dos acciones dependiendo de lo que se necesite realizar para avanzar en el parseo de la entrada.
- Un paso de la acción Shift avanza en el puntero de entrada por un token. Ese simbolo “shifteado” se convierte en el nuevo nodo del árbol sintáctico.
- Un paso Reduce, aplica una regla gramatical completa a alguno de los arboles de parseo, uníendolos como un solo árbol con un nuevo token raiz.
Si el input no tiene errores de sntaxis, el parse continua con estos pasos hasta que el input haya sido consumido del todo y los árboles de parseo se haya reducido a un solo AST representando todo el input válido. La eficiencia de un parser LR radica en que pueda ser determinístico. Como se mencionó antes, teniendo un lookahead, o mecanismo para leer los próximos k tokens para determinar con mayor certeza el camino a elegir es fundamental.
A continuación se tiene una gramática (arriba a la izquierda) para sumar dos términos cuyo valor puede ser “id” y tenemos un texto de entrada que es “id + id”. A la derecha tenemos un esquema de acciones, en el que tendremos una regla de accion Sn, en la que dependiendo la entrada, si es un token “id”, “+”, “$” que se hará si un shift, aceptación o reducción. En caso de que no se puedan avanzar en el parseo porque se fallo en la regla, ocurrirá un fallo y se vera de seguir por otra regla por backtracking, si no hay otras reglas se producirá un error, y se terminará la ejecución. Si se termina en un estado S1, en el que solo queda un input “$”, se habrá terminado satisfactoriamente el parser, esta tabla de acción puede verse como un DFA. El goto indica que tipo de regla derivan de estos. Abajo, se puede ver la ejecución, en la que se empieza siempre con el stack vacío, y se tiene que llegar a tener un AST completo, sin miembros sin reducción y con el Input vacío. Entonces se empieza con un estado de acción S0 y al leer el primer símbolo S0, se produce un shift 3, y se detectará el primer token id 3, como id puede reducirse a T, entonces se aplica reduce P3, de la regla S3, el 3 después del token en el stack representa la regla, entonces al tener id $, donde $ es el caracter o token nulo, entonces queda T 2, siendo 2 la regla que implica el goto para avanzar de estado, luego de esto se procesa el + y al existir una relga para este shift 4, quedará como T 2 + 4 en el stack, y se seguira avanzando de acuerdo a la acciones descriptas en la tabla que esta abajo.
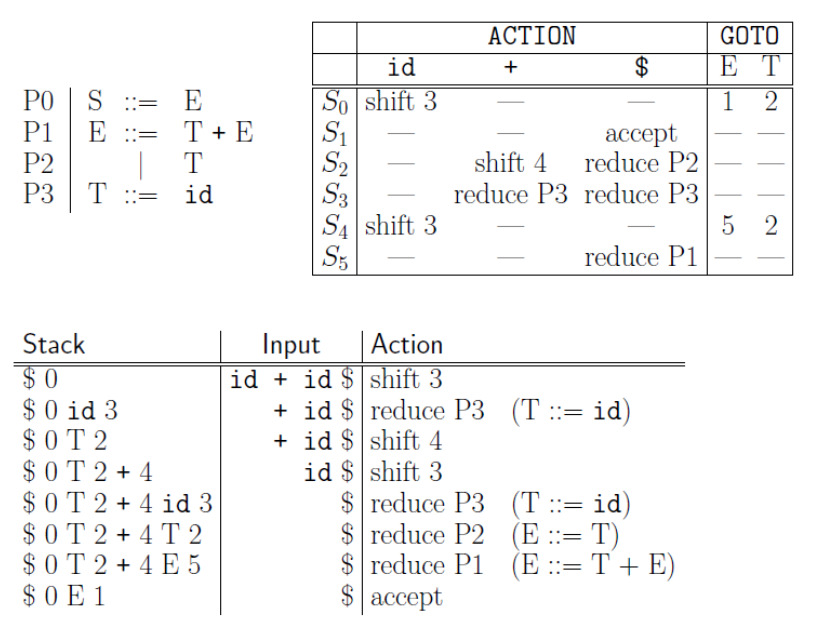
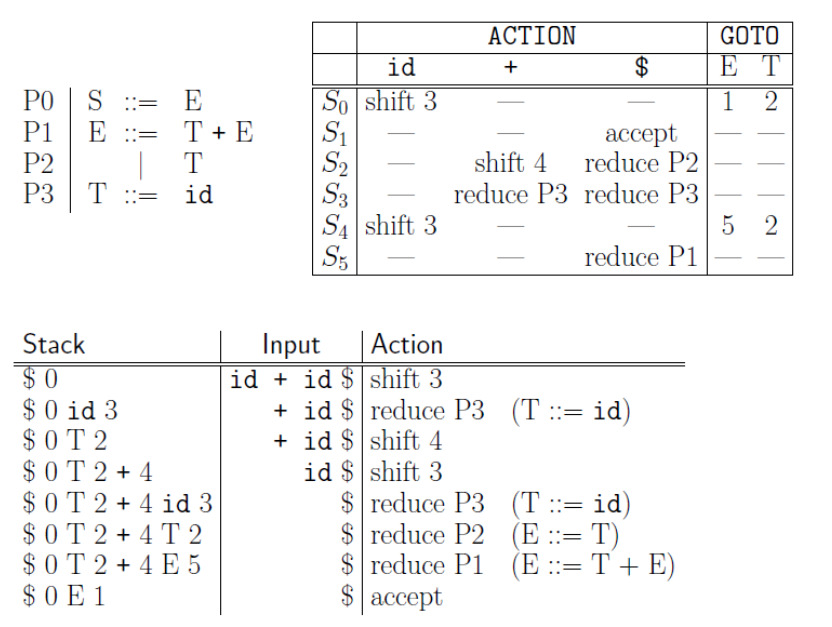
Construcción de la tabla del parser LR(1)
TODO
Parser combinators
Luego volvimos a retomar la idea de parsers combinators, en la que tenemos un parser top-down, con backtracking y guessing, cuidado con la recursividad por izquierda, en este caso. Se volvió a hacer énfasis sobre lo explicado en encuentros anteriores. Luego de eso se realizó el ejercicio puesto como tarea del encuentro anterior
#Esto es un comentario
class NombreDeClase
{
def bleh (arg1, arg2)
{
3 + 4
42
"Hola"
}
}Agregando el caso de tener una estructura de bloques if/else, una solución a esto esta en